Supercharge your Shopify promotions
Since 2016, our apps have been used by thousands of Shopify stores to boost their sales and dramatically grow their business.
Over 270 five star ratings on the Shopify App Store
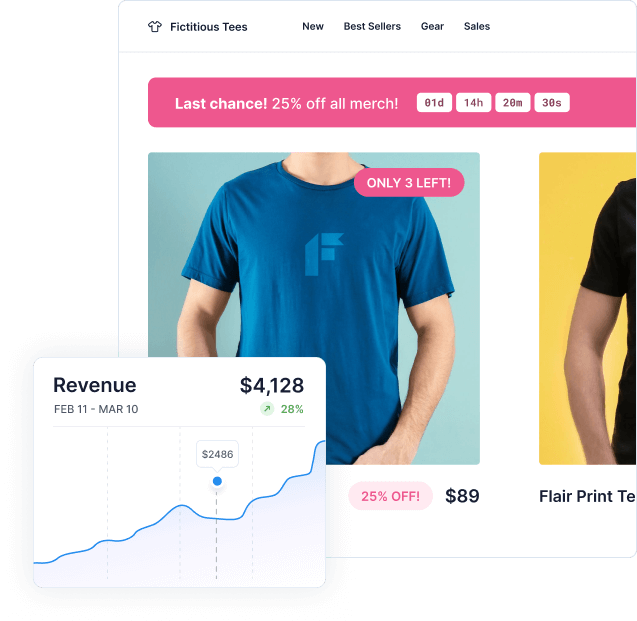
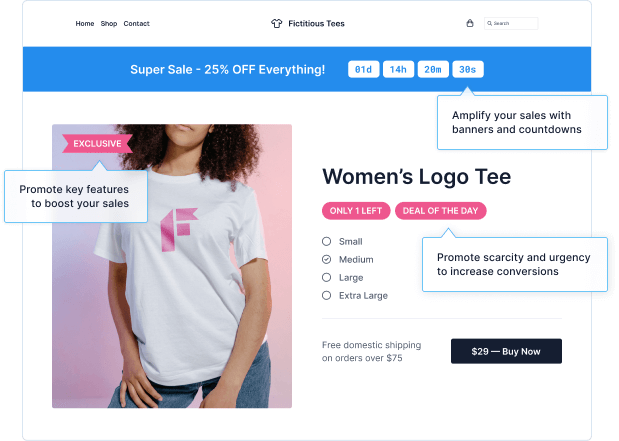
Since 2016, our apps have been used by thousands of Shopify stores to boost their sales and dramatically grow their business.
 of Shopify stores
of Shopify stores
Flair is a must-have for any online store. It helps increase sales with advanced promotions and automatic product labels, badges, stickers & more.
Boost sales and grow your business with targeted, automated product badges and promotions.
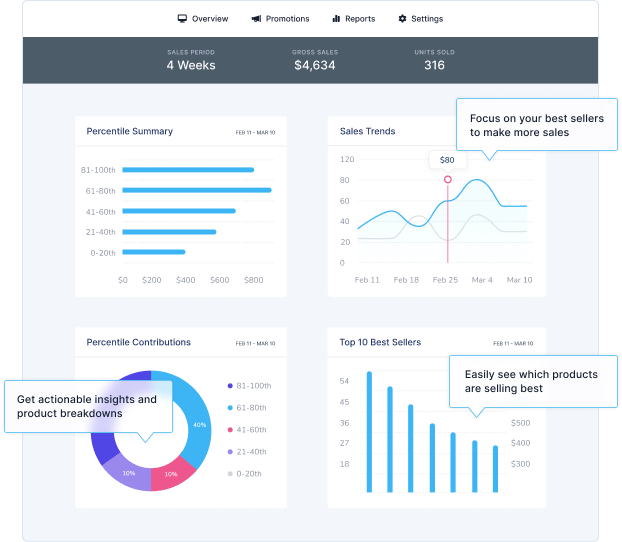
Maximize sales by focusing on your best-selling products.
Shopify tips and tricks to help your store succeed.
Check out our latest product updates to see what's new.
Tactics and guides for managing and growing e-commerce stores.





